巴西电商 Olist Store 数据分析项目目录¶
项目介绍¶
- 领域:电商
- 数据来源:Olist Store 巴西电商平台
- 数据情况:真实订单交易数据
- 时间跨度:2016年至2018年
- 分析工具:
- 代码语言:Python
- 数据库:Mysql
- 可视化工具:Tableau 2019 professional edition、Matplotlib、Seaborn
分析目的¶
对巴西电商平台 Olist Store 的销售数据进行分析,并给出改善建议。
框架确定¶
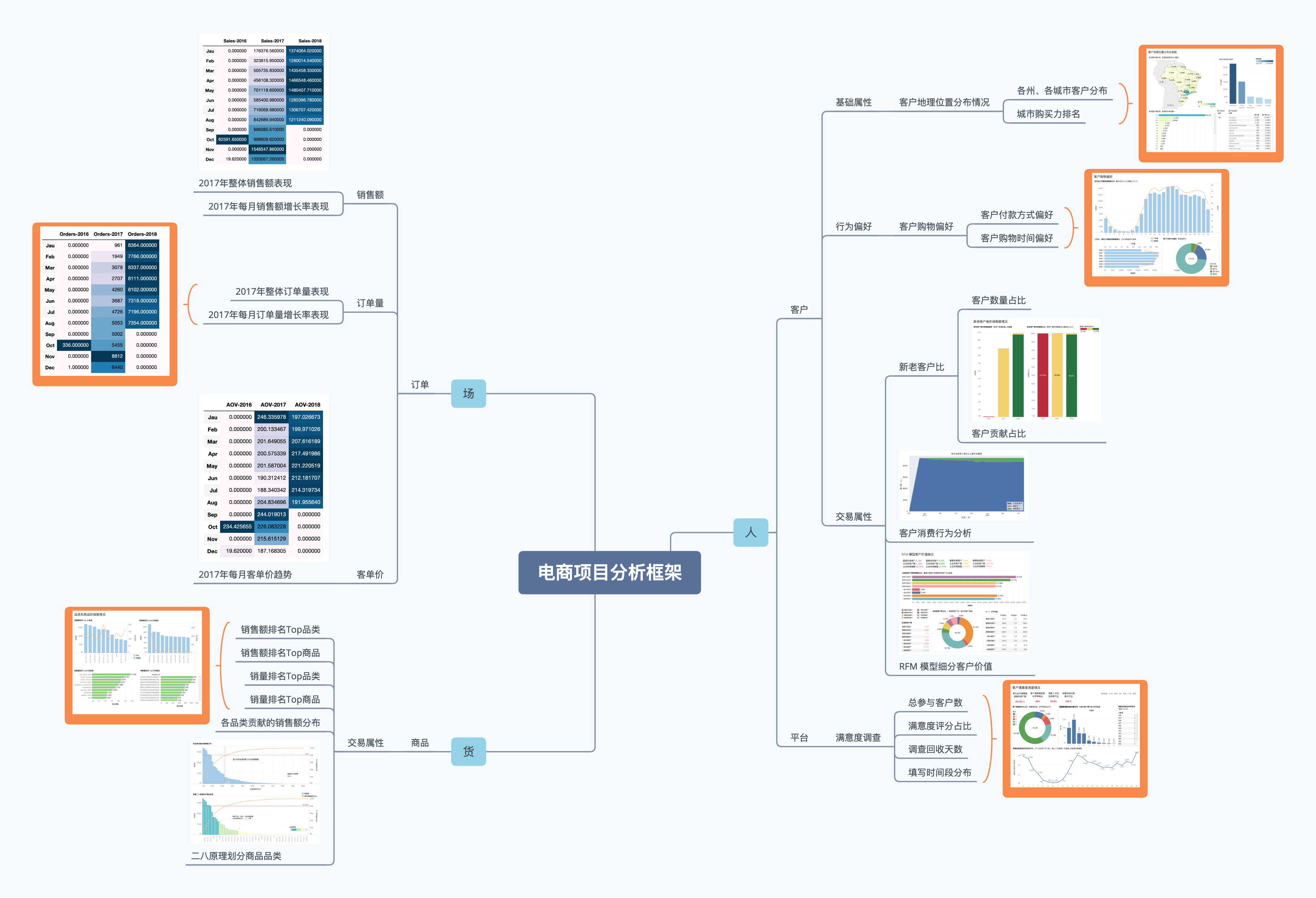
分析框架¶
本次分析将从人、货、场这三个视角入手,框架如下图:
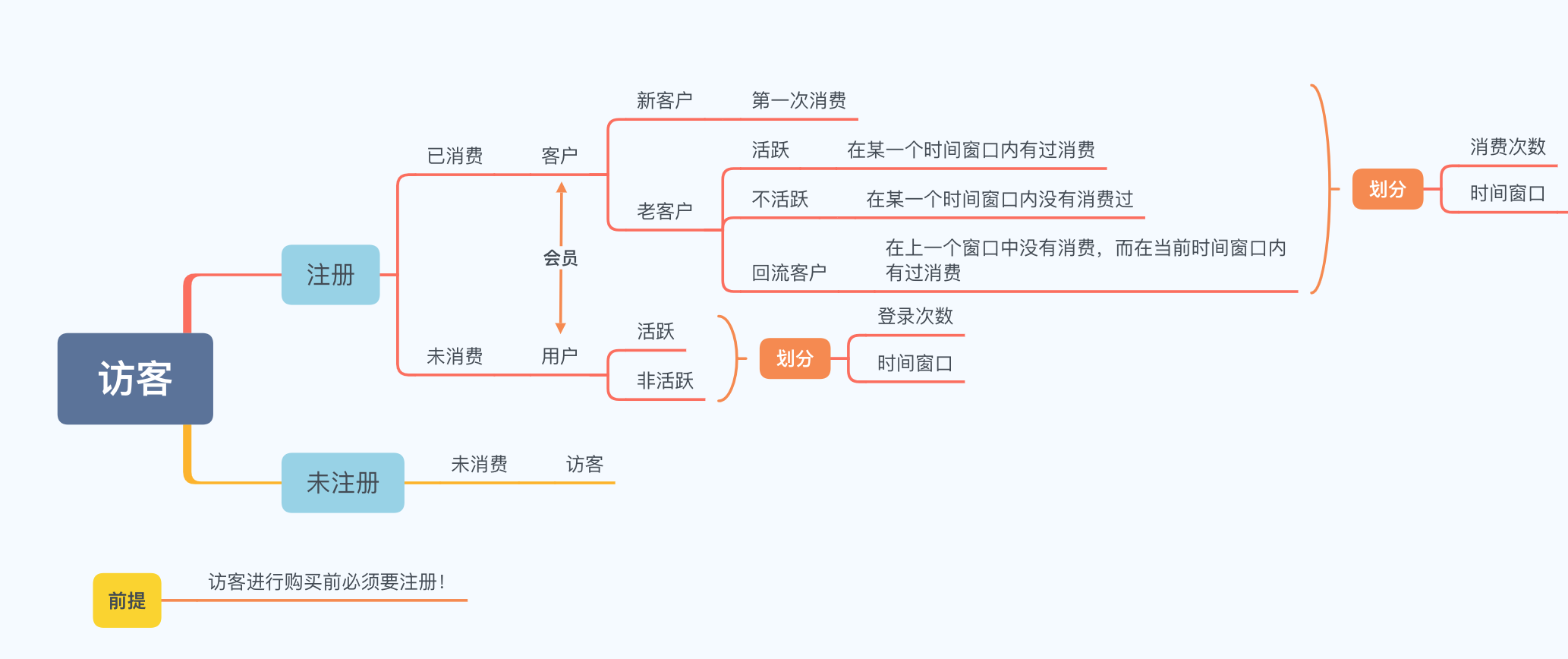
明确定义¶
在电商领域,经常会出现用户、访客、客户、顾客、会员、注册会员等字眼,为了最大程度上避免理解误差,本次分析将遵循如下分类标准:
分析报告¶
整体销售情况分析¶
原数据集中只有2017年的数据是整年的,2016和2018都或多或少不完整,所以这里只分析2017年的数据。
2017年整体销售额表现¶
- 2017年销售额整体呈上升趋势,在11月销售金额达到顶峰,且远高于其他月份,1月销售金额最低,3,5月达到了阶段性的小高峰;
- 从每月增长率来看,2、3、5、11月增速较快,其他月份表现平平;
- 总的来说,后半年的表现远好于前半年,而且随着月份的增大,销售额也有明显的增加。
2017年整体订单量表现¶
- 2017年订单量变化趋势与销售额是一样的,下半年整体高于上半年;
- 2017年订单量增长率变化与销售额增长率是一样的,2、3、5、11月增速较快,其他月份表现平平。
2017年每月客单价趋势¶
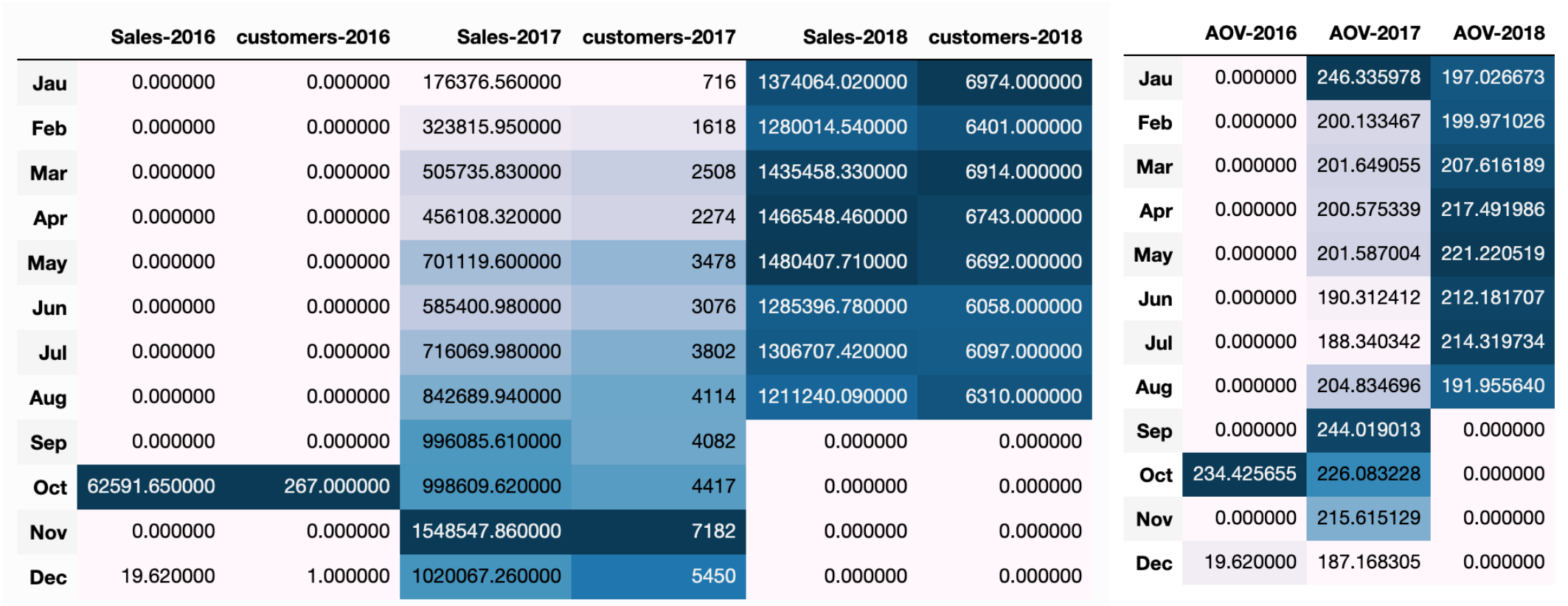
- 每月的消费人数呈不断上升趋势,但是客单价总体浮动范围不是很大,稳定在200左右。
商品情况分析¶
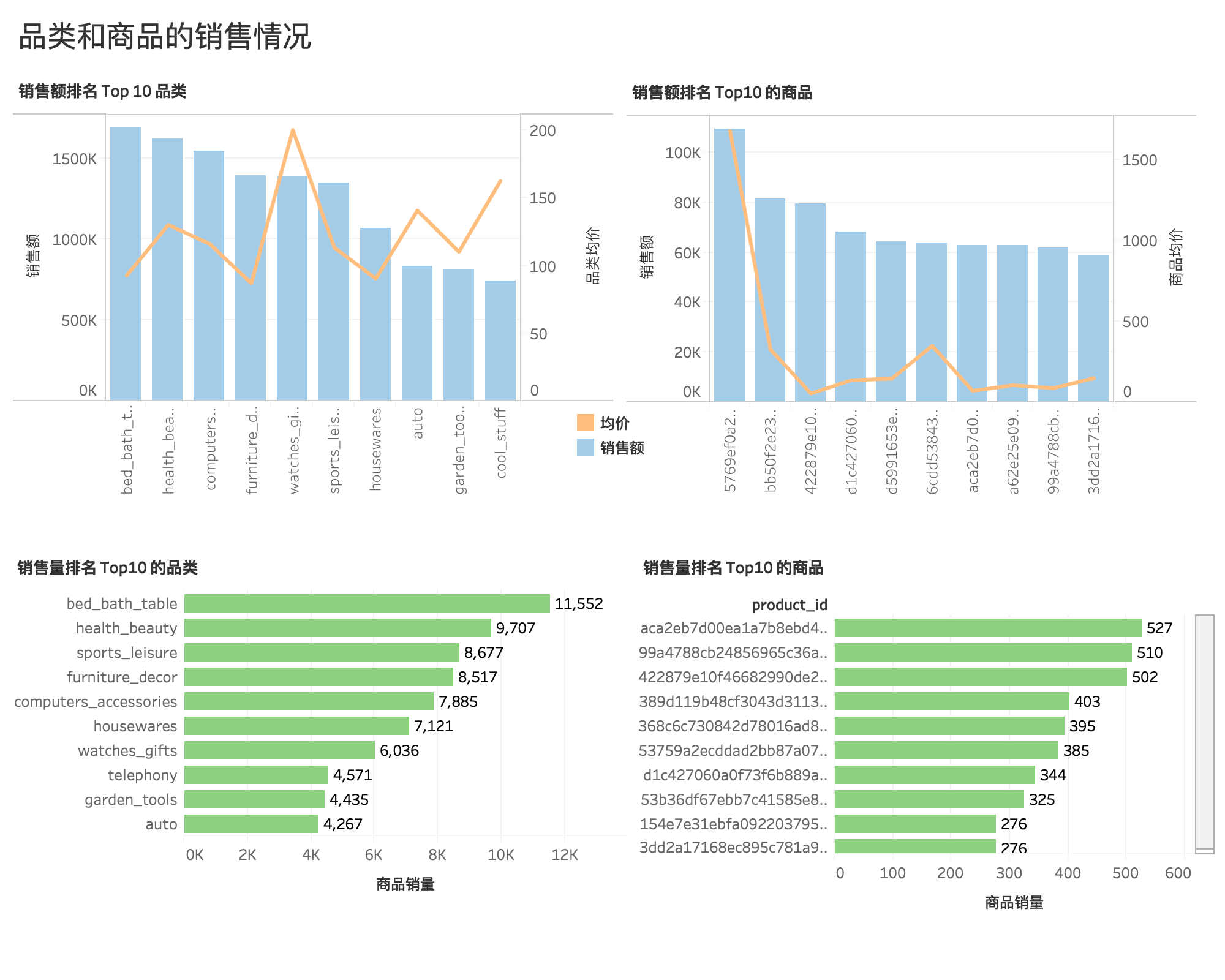
商品和品类销售情况¶
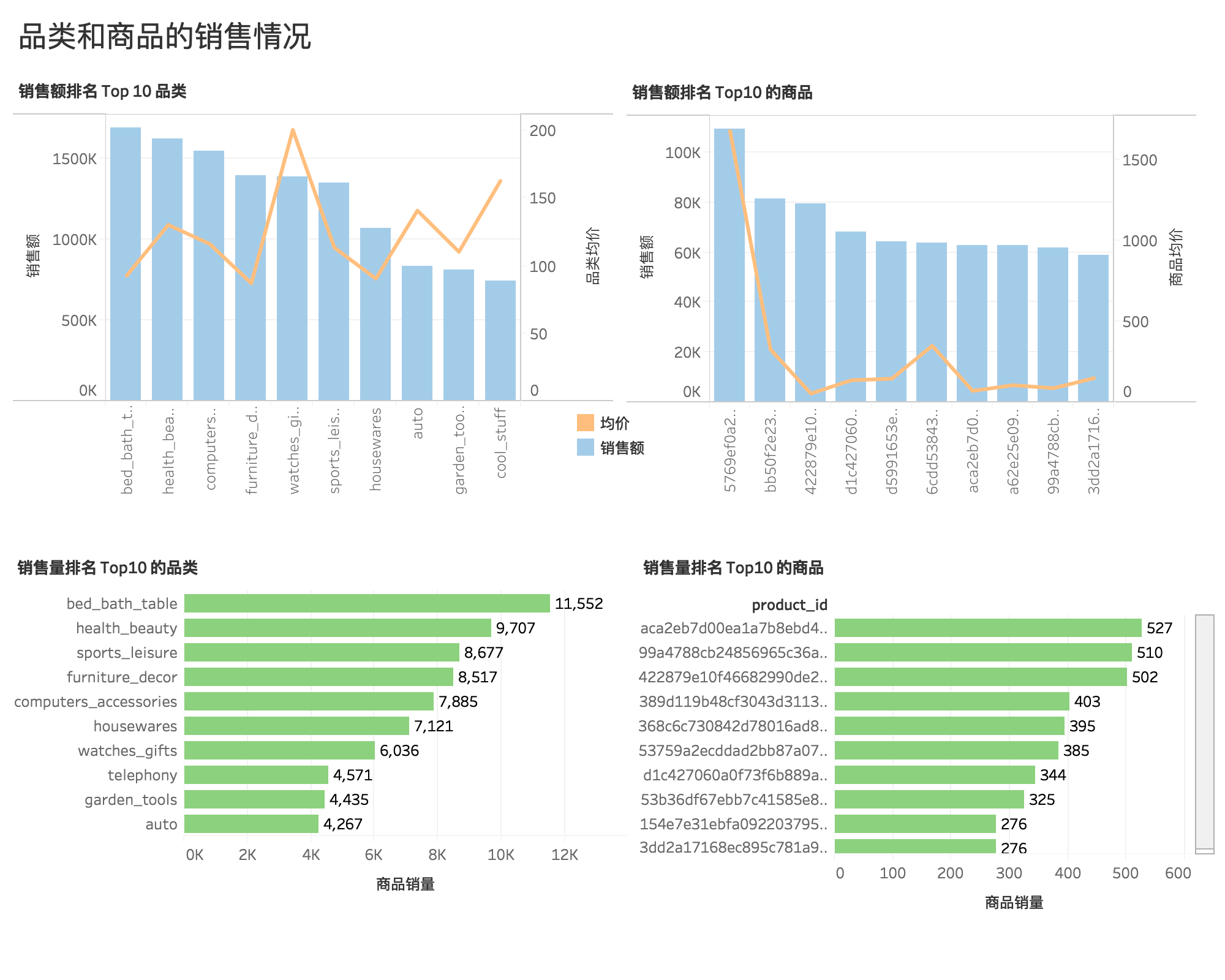
- 销量和销售额最高的是床上用品、洗漱用品、桌子类的品类商品。
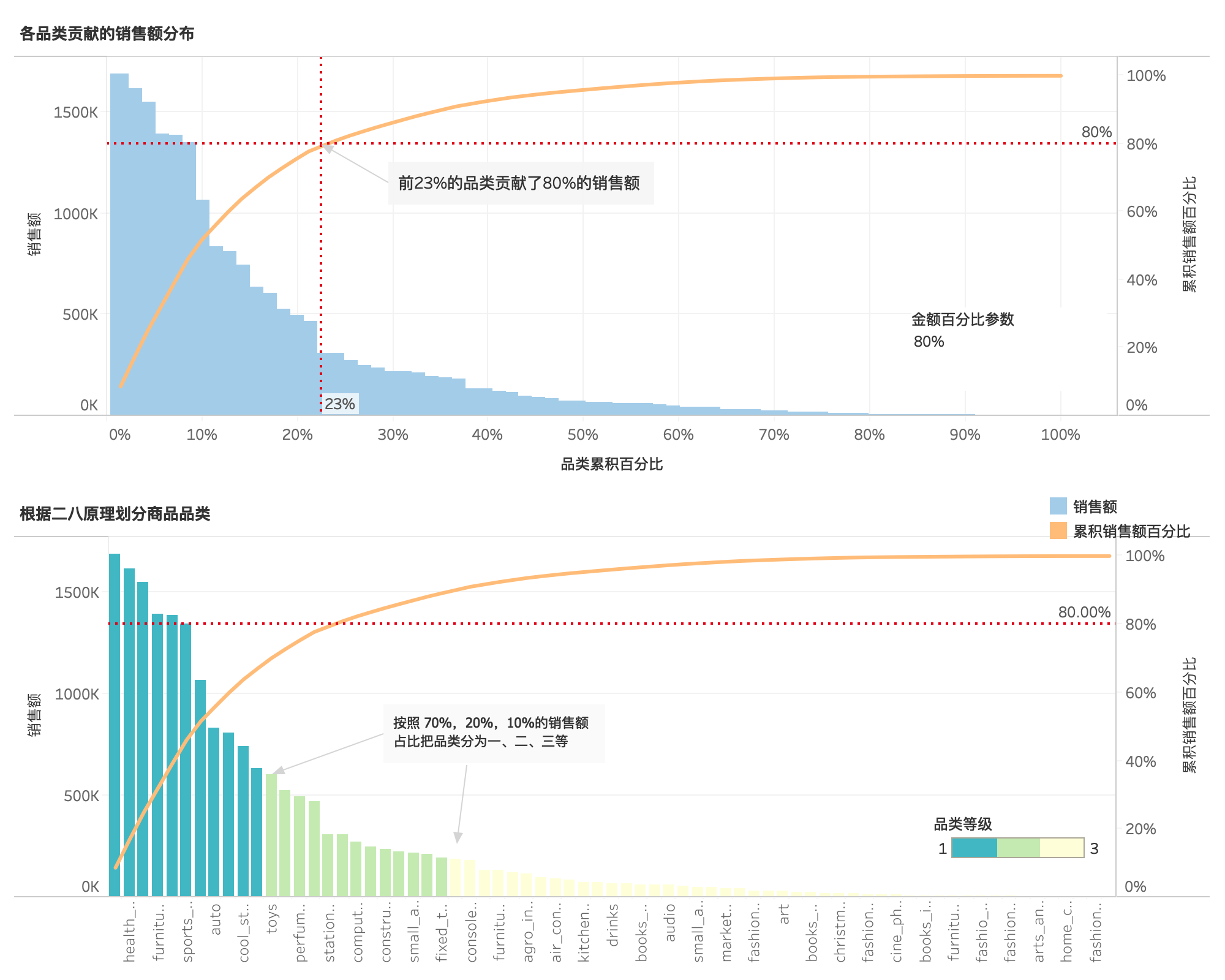
各品类贡献的销售额分布¶
- 不同品类的销售额贡献对比,23%的商品品类贡献了80%销售额,符合二八原理。
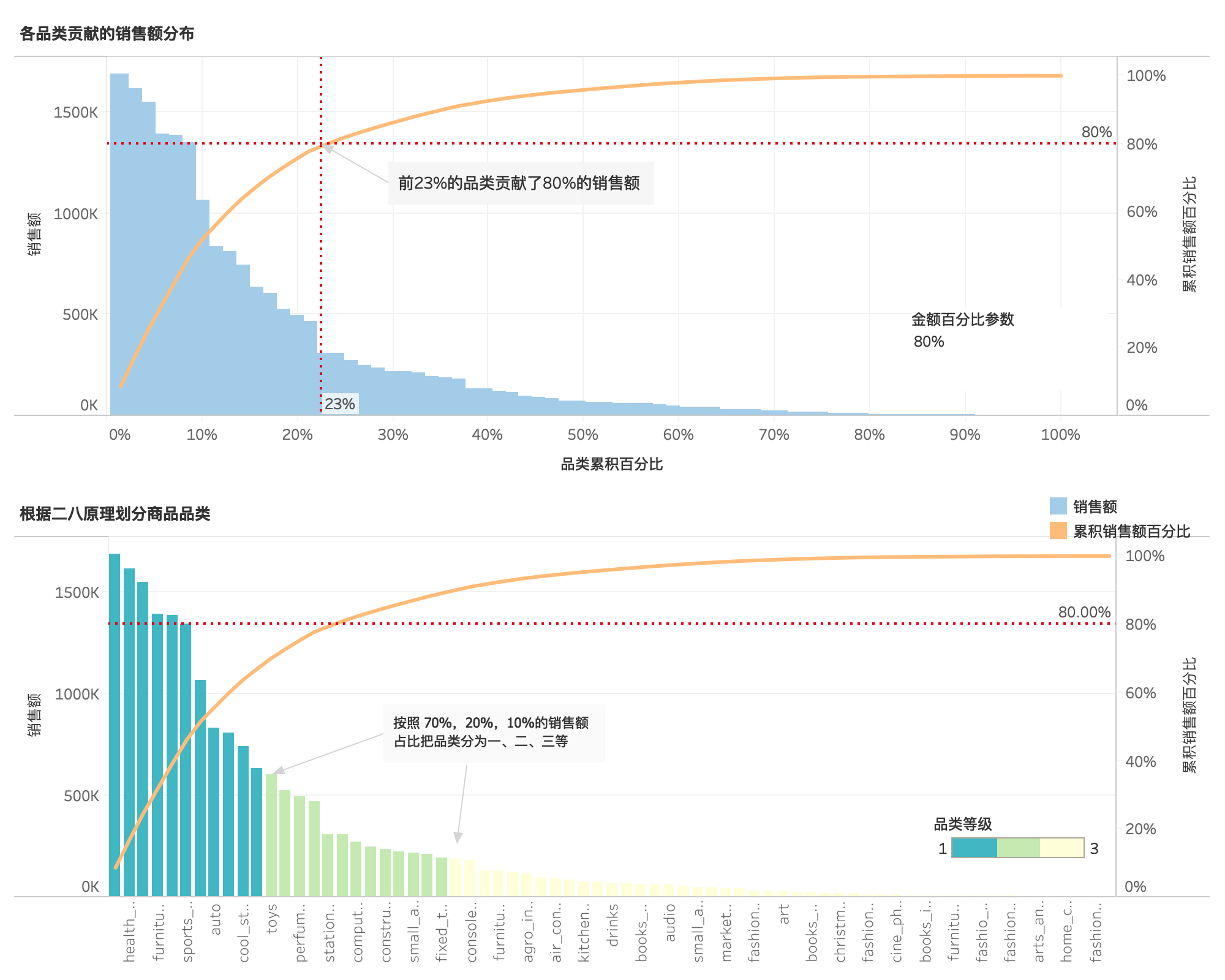
根据二八原理划分商品品类¶
- 同时按照70%,20%,10%的销售额比重把商品品类分为一、二、三等级,便于优化产品结构和资源分配。
客户情况分析¶
客户地理位置分布情况¶
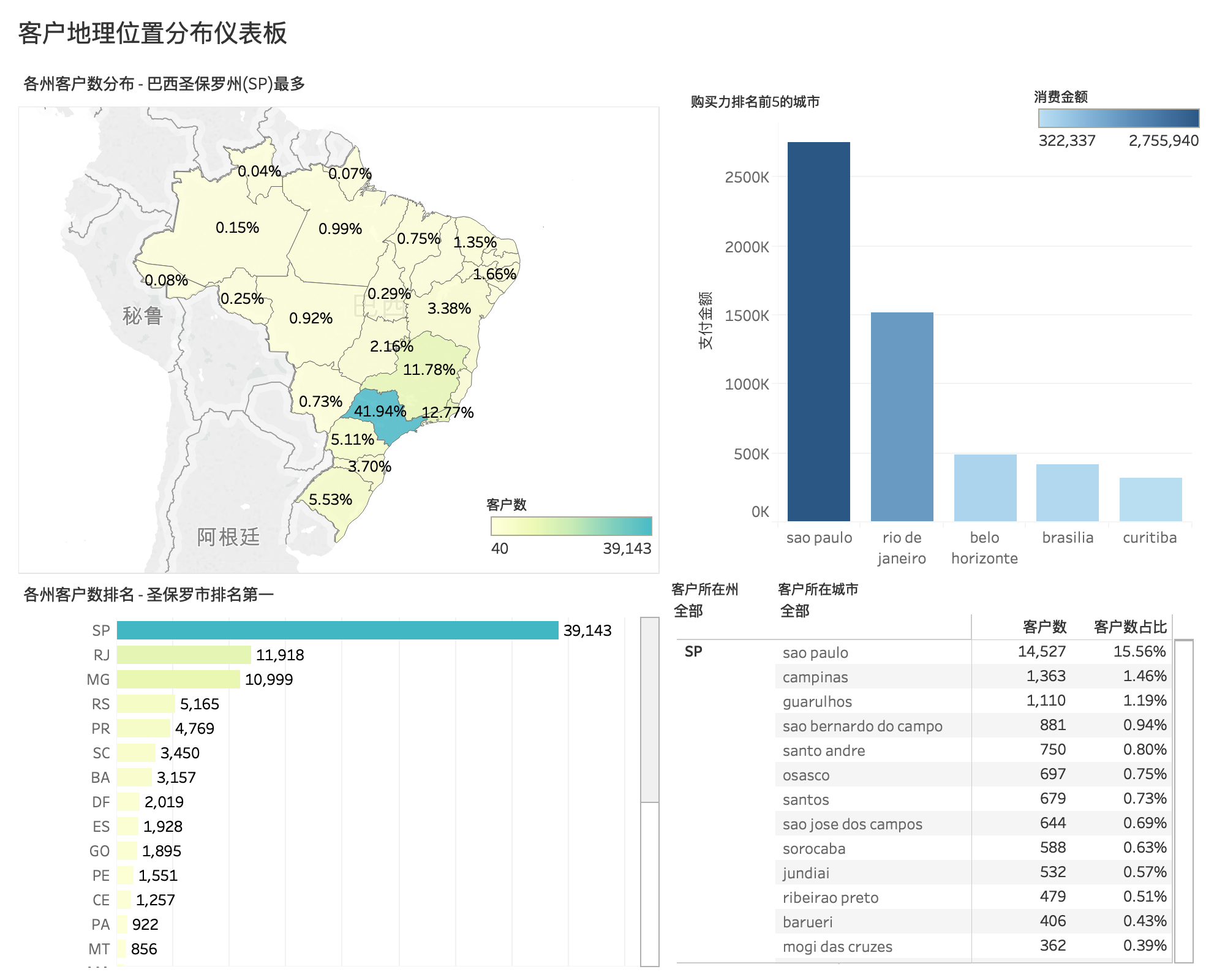
各州、城市客户分布¶
Olist 客户主要集中在7个州和9个城市,巴西圣保罗州(SP)、里约热内卢州(RJ)、米纳斯吉拉斯州(MG)这三个州的客户数处于前列。其中,巴西圣保罗州(SP)是客户数最多的州,占总客户数的 41.94%,而客户数分布最多的城市是巴西圣保罗州的 sao paulo(圣保罗) ,约占 15.56%。
城市购买力排名¶
购买力排名的前三强为 sao paulo(圣保罗),rio de janeiro(里约热内卢),belo horizonte(贝洛奥里藏特)。
客户购物偏好¶
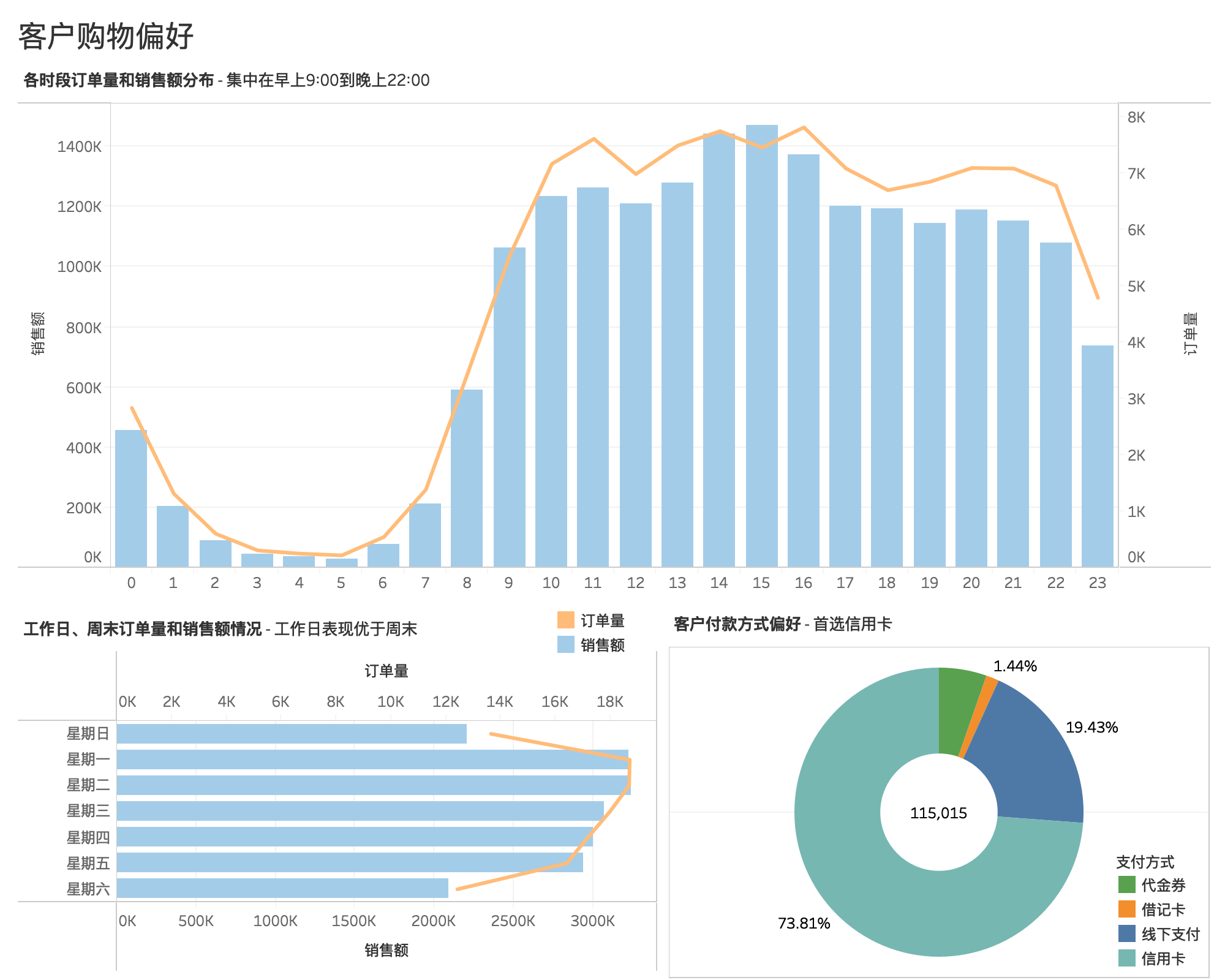
客户付款方式偏好¶
115015个订单中,客户付款方式首选信用卡 credit_card 支付,占比高达73.81%,其次是通过线下付款的方式 boleto(巴西主流的线下支付工具),占比19.43%,代金券 voucher 和借记卡 debit_card 分别占比5.32%和1.44%。
客户购物时间偏好¶
- 客户下单时间主要集中在早上9:00到晚上22:00,用户比较活跃,下单量比较密集。
- 建议将工作人员上班时间定在上午9:00前,且要确保晚上22:00左右有足够的工作人员为客户服务。
- 下午13:00-16:00用户下单量较高,建议增大该时间段内的促销活动及商品推送服务;
- 工作日的订单量和销售金额表现优于周末。周一、周二订单量达到每周高峰,周六日的订单量达到每周低估
- 建议将平台工作人员休息时间安排在周六日。
新老客户占比¶
新老客户数占比¶
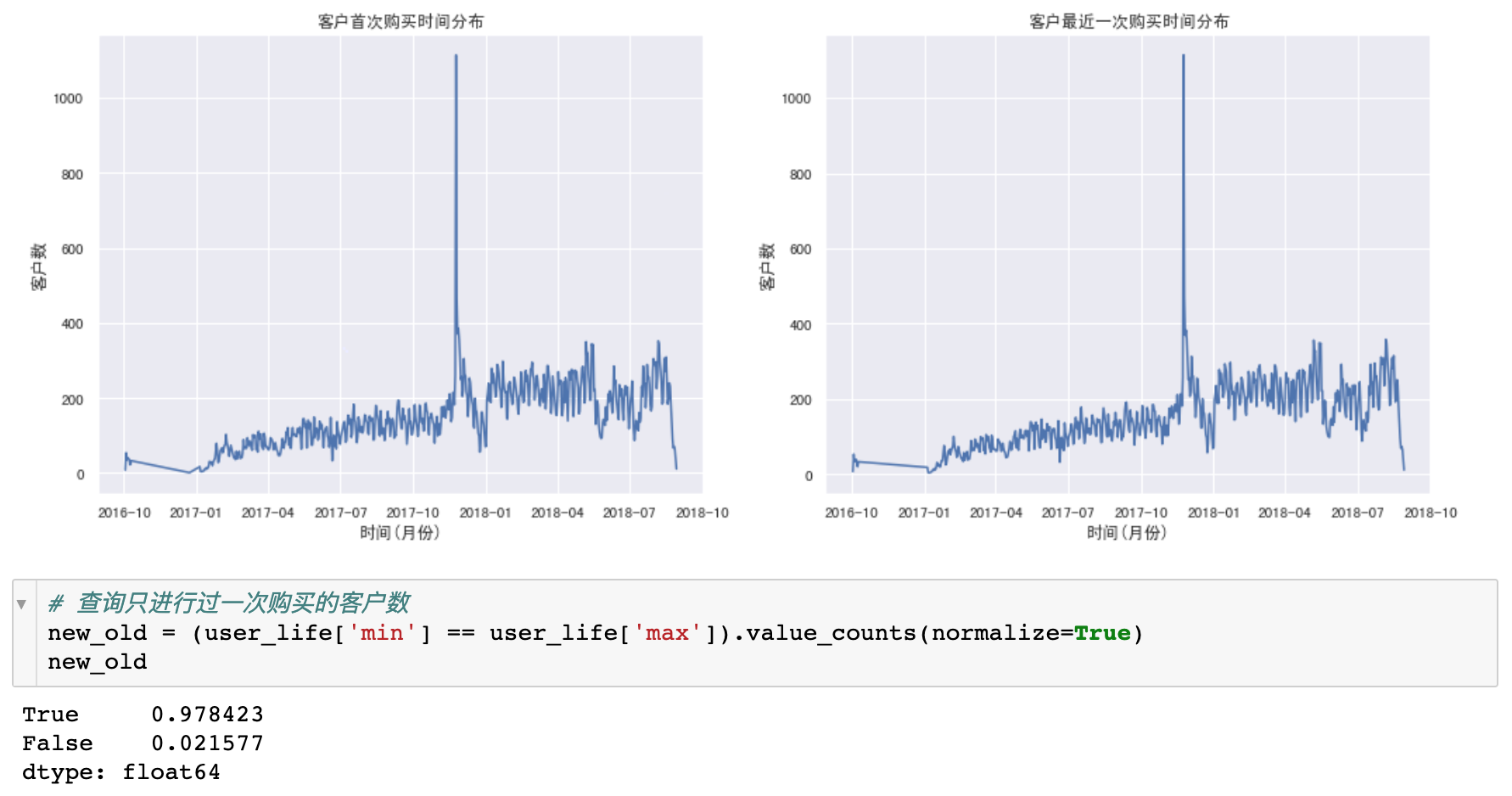
- 从分布可以看到,
- 客户第一次购买的分布和最近一次购买的分布十分相识,说明大部分用户只购买了一次,就再也没有购买过了。
- 在2017年11月,新用户数暴涨。
- 从客户数可以看出,新客户数占总客户数97.8%,老客户数占总客户数2.2%
新老客户贡献占比¶
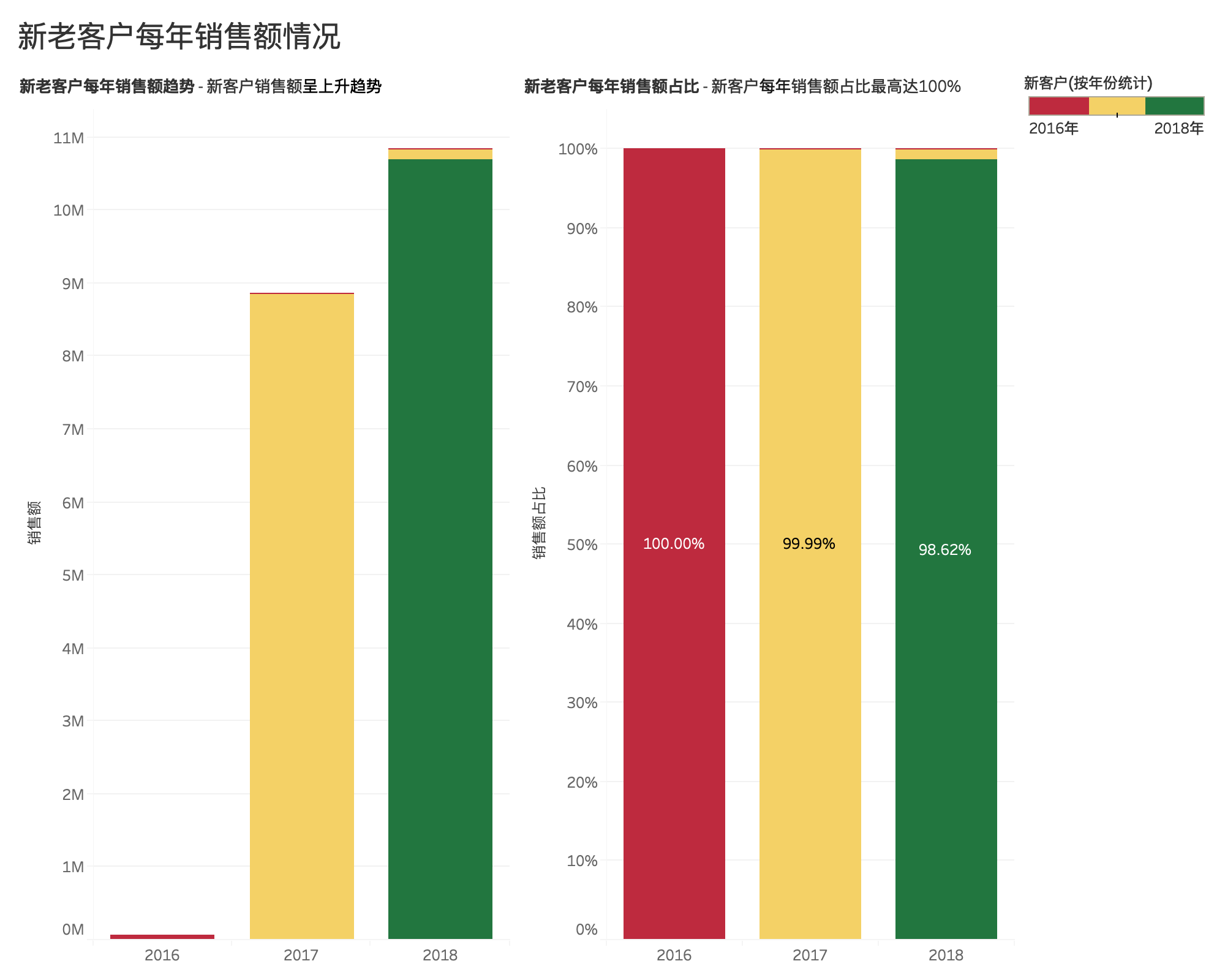
再结合新老客户贡献占比情况,可以得出,大部分客户只购买一次,说明该电商平台在老客户维系工作方面没有到位,亟需改善。
客户消费行为分析¶
按照客户的消费行为,对客户简单划分成几个层:新用户、活跃用户、不活跃用户、回流用户。
- 新客户:第一次消费的客户
- 活跃客户:连续两个时间窗口都消费过的客户
- 不活跃客户:时间窗口内没有消费过的活跃客户
- 回流客户:回流客户是在上一个窗口中没有消费,而在当前时间窗口内有过消费
这里把时间窗口定为1个月
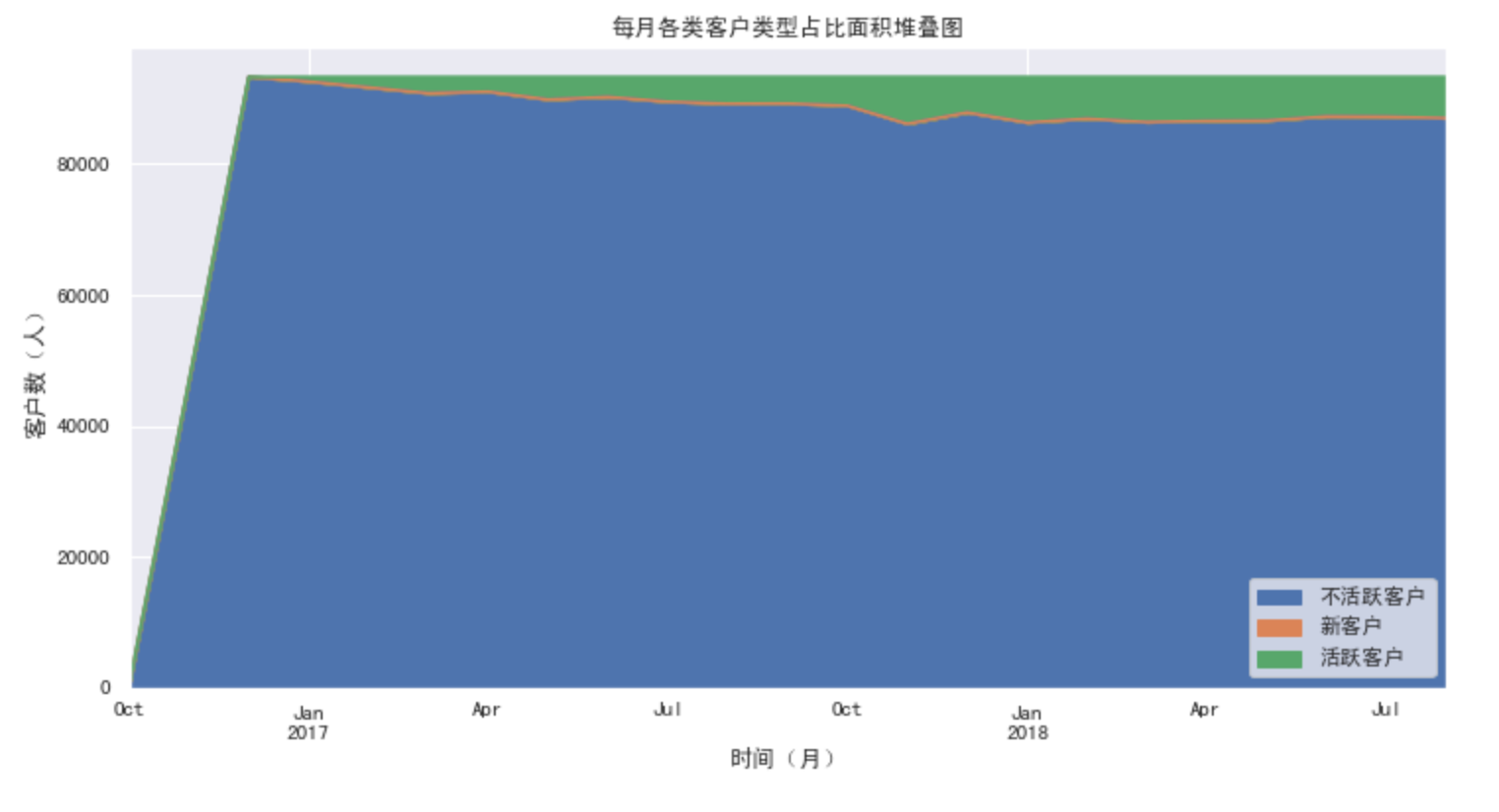
- 蓝色的不活跃客户始终是占据大头的,这也跟我们之前的图表结果相符,大部分客户购买一次后基本都流失完了。
- 绿色的活跃客户相对稳定,是属于核心客户群。
- 橙色的新客户,相对稳定。
- 回流用户为零。
结合不活跃客户和回流用户,如果电商平台能在老客户维系工作上取得突破,会给平台带来很大的增长空间。
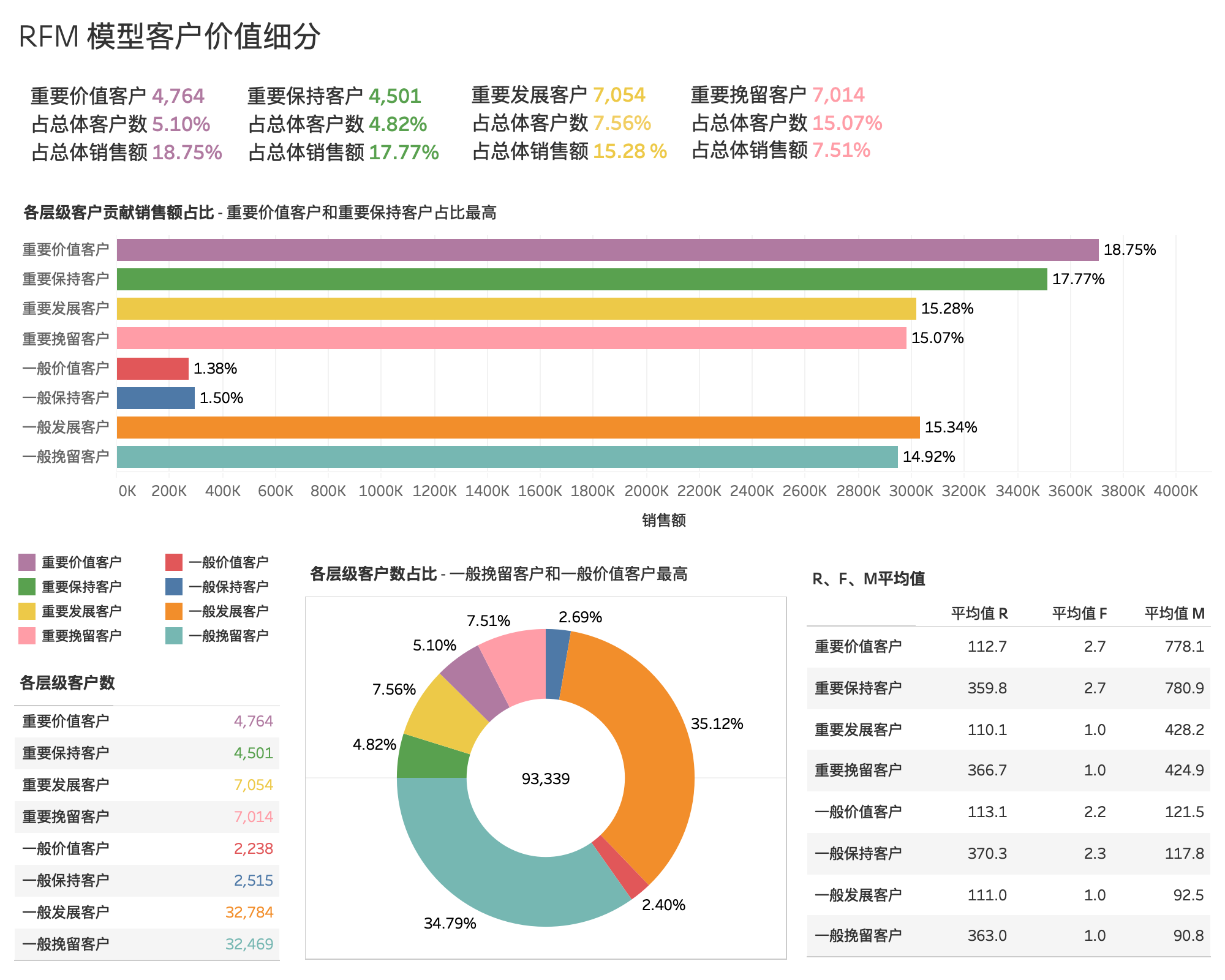
客户价值分析-RFM模型¶
平台情况分析¶
客户满意度调查情况¶
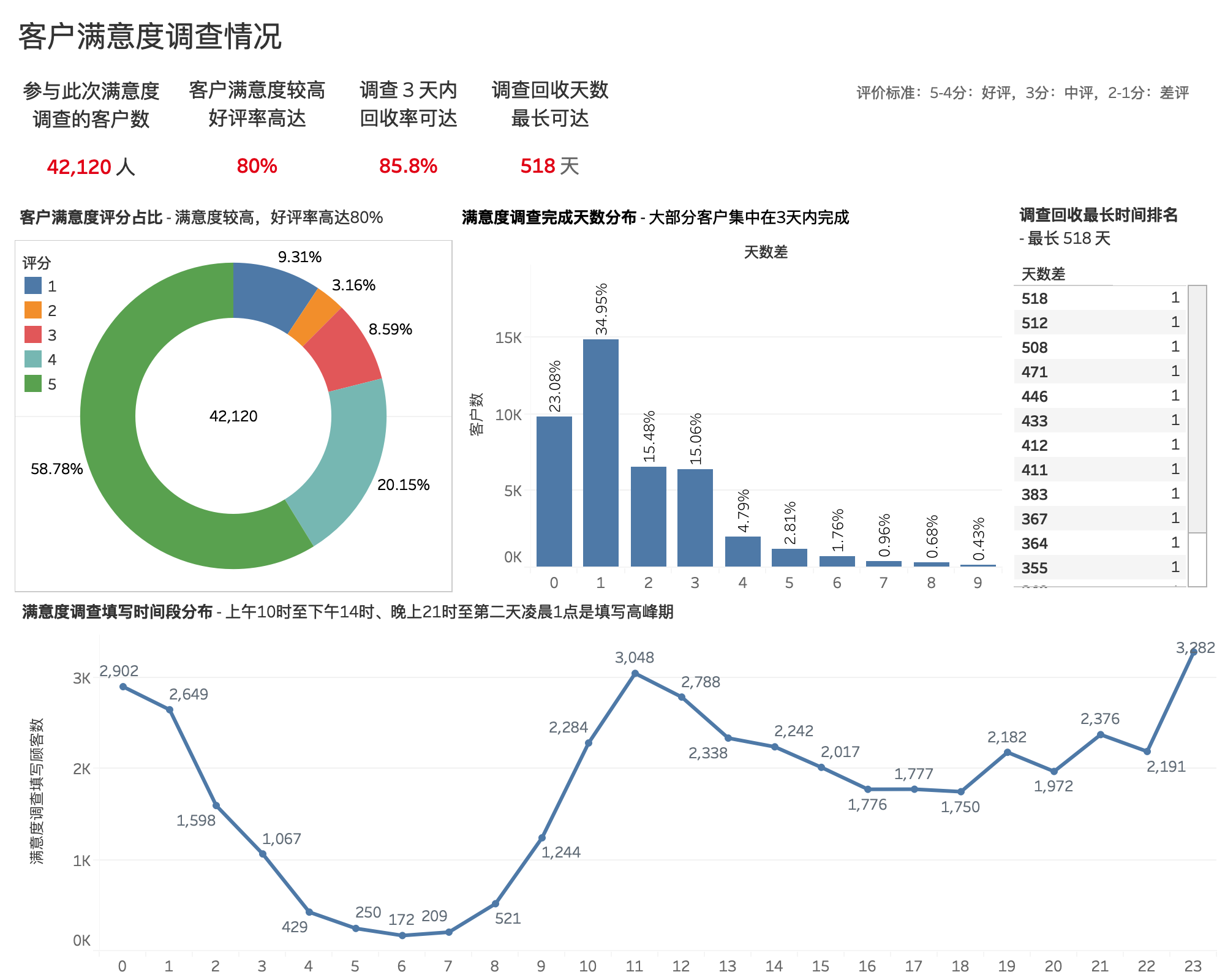
客户满意度评分占比¶
- 客户对该电商平台满意度较高,好评率高达80%。
- 以(1-2分:差评,3分:中评,4-5分:好评)为评价标准。参与满意度调查的客户数一共有4,213名,其中评价5分占比最高,为58.78%,4分占比20.15%,好评率近80%,用户满意度较高;但1分和2分合计占比12.4%左右,平台还有一定的提高空间。
客户满意度调查填写时间段¶
- 上午10时至下午14时、晚上21时至第二天凌晨1点这两个时间段是客户完成调查的高峰期
客户满意度调查完成天数¶
- 满意度调查发布3天内,回收率达 85.8%
- 大部分客户会在调查发布当天或者隔1-3天填写并提交
- 1-3天内未填写的客户,大概率会遗忘,调查回收最长可达 518 天
建议
- 为了,提高调查回收率,建议调查发布1周后,提醒未填写的用户
- 可选择在上午10时至下午14时、晚上21时至第二天凌晨1点这两个时间段发布满意度调查或者提醒尚未填写的客户
结尾¶
本文分别人、货、场这三个视角入手一家巴西电商的销售、商品、客户情况,并根据分析结果给出一些有利于拓展客户、提升销量的办法。当然,这份数据集还包含信息很多,还可以进行其它一些方面的分析,在后期再添加。
分析主体¶
数据集概要¶
巴西电子商务平台 Olist Store 提供的从2016年至2018年之间10万多条的真实订单交易数据。
- 数据集来源:Kaggle 公开数据集
- 数据集大小:10万多条的真实订单数据(脱敏)
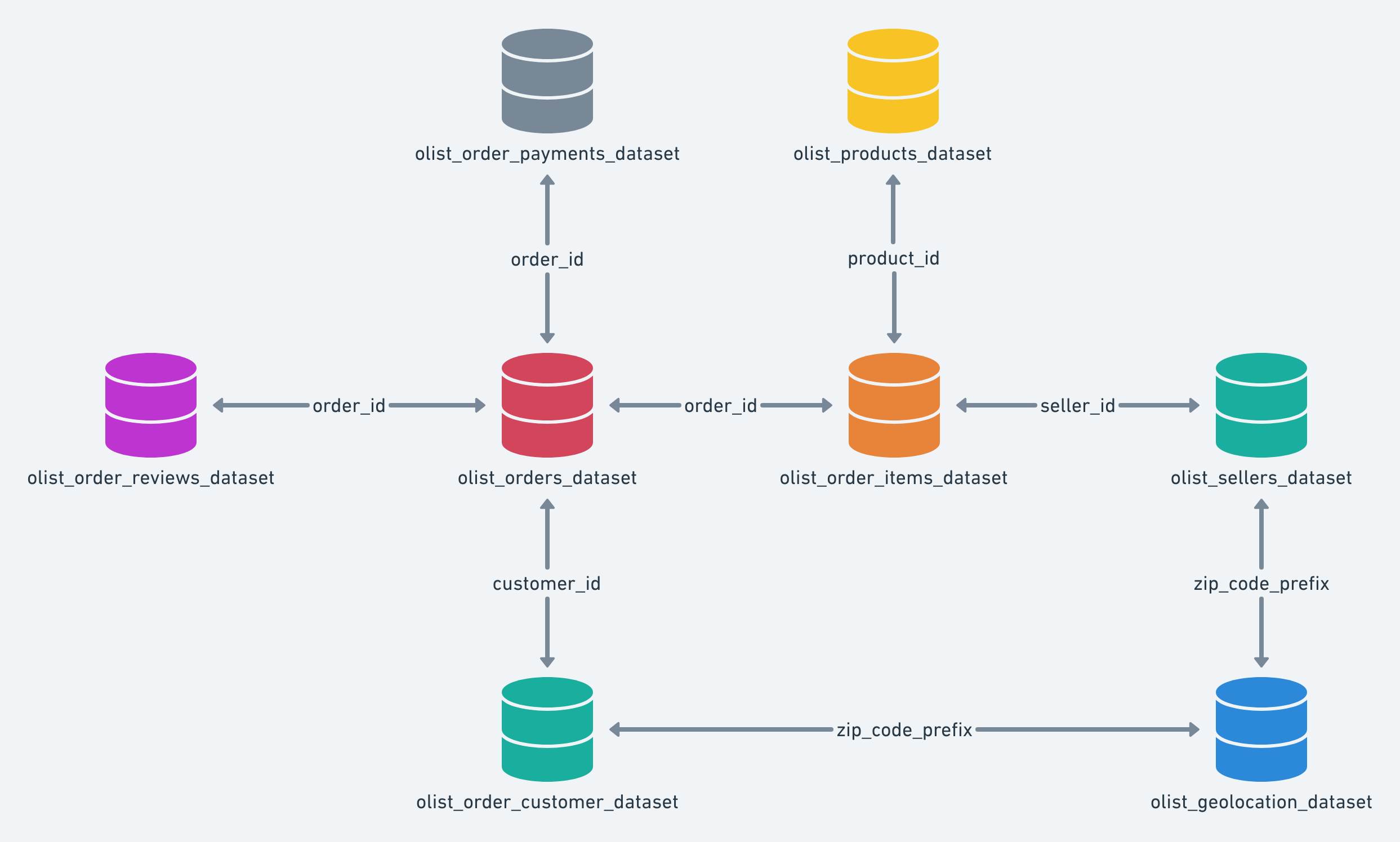
- 该数据集包含9张表
| 表名 | 说明 |
|---|---|
| olist_customers_dataset.csv | 客户及其位置的信息 |
| olist_geolocation_dataset.csv | 巴西邮政编码及其纬度/经度坐标信息 |
| olist_Order Items Dataset.csv | 每个订单中购买的商品的数据 |
| olist_Payments Dataset.csv | 订单付款的数据 |
| olist_Order Reviews Dataset.csv | 客户所做评论的数据 |
| olist_Order Dataset.csv | 订单交易数据 |
| olist_Products Dataset.csv | Olist销售的产品的数据 |
| olist_Sellers Dataset.csv | Olist完成订单的卖家的数据。 |
| product_Category Name Translation.csv | 将商品名从葡萄牙语翻译为英语 |
各表之间的关系如下:
导入相关库¶
# 导入相关库
import numpy as np # 科学计算工具包
import pandas as pd # 数据分析工具包
import matplotlib.pyplot as plt # 图表绘制工具包
import seaborn as sns # 基于 matplot, 导入 seaborn 会修改默认的 matplotlib 配色方案和绘图样式,这会提高图表的可读性和美观性
import os,pymysql
from sqlalchemy import create_engine # 数据库
plt.rcParams['font.sans-serif'] = ['SimHei'] # 中文字体设置-黑体
plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
sns.set(font='SimHei') # 解决Seaborn中文显示问题
# 在 jupyter notebook 里面显示图表
%matplotlib inline
获取数据集¶
# 目录下所有 CSV 文件
table_list= [filename for filename in os.listdir('.') if filename.endswith('.csv') ]
print(table_list)
# 获取数据集
orders = pd.read_csv("olist_orders_dataset.csv")
payments = pd.read_csv("olist_order_payments_dataset.csv")
customers = pd.read_csv("olist_customers_dataset.csv")
reviews = pd.read_csv("olist_order_reviews_dataset.csv")
order_items = pd.read_csv("olist_order_items_dataset.csv")
products = pd.read_csv("olist_products_dataset.csv")
seller = pd.read_csv("olist_sellers_dataset.csv")
geo = pd.read_csv("olist_geolocation_dataset.csv")
pro_trans = pd.read_csv("product_category_name_translation.csv")
理解数据集¶
通过预览数据,了解所有字段和其含义。
| 字段 | 说明 |
|---|---|
| product_id | 商品ID |
| seller_id | 商家ID |
| order_id | 订单ID |
| customer_id | 订单对应的用户ID(每个订单有一个唯一的customer_id) |
| order_status | 订单状态 |
| order_purchase_timestamp | 下单时间 |
| order_approved_at | 付款审批时间 |
| order_delivered_carrier_date | 快递揽收日期 |
| order_delivered_customer_date | 订单送达日期 |
| order_estimated_delivery_date | 预计送达日期 |
| customer_unique_id | 客户唯一标识符 |
| customer_zip_code_prefix | 客户邮政编码前5位 |
| customer_city | 客户所在城市 |
| customer_state | 客户所在的州 |
| review_id | 评论ID |
| review_score | 评价得分,客户在满意度调查中给出的注释范围为1到5。 |
| review_comment_title | 评论标题(葡萄牙语) |
| review_comment_message | 评论内容(葡萄牙语) |
| review_creation_date | 发出满意度调查日期 |
| review_answer_timestamp | 客户满意度回复日期 |
| payment_sequential | 付款序列(客户可以使用多种付款方式支付同一个订单) |
| payment_type | 付款方式 |
| payment_installments | 分期付款期数 |
| payment_value | 交易金额 |
| order_item_id | 序号,用于标识同一订单中包含的商品数量。 |
| price | 商品价格 |
| freight_value | 单个商品的运费(如果订单包含多个商品,总运费平摊到每个商品中) |
| shipping_limit_date | 显示将订单处理到物流合作伙伴的卖家发货限制日期 |
| seller_zip_code_prefix | 卖家邮政编码前5位 |
| seller_city | 卖家所在城市 |
| seller_state | 卖家所在州 |
| product_category_name | 产品品类名称(葡萄牙语) |
| product_category_name_english | 产品品类名称(英语) |
| product_name_lenght | 产品名称长度 |
| product_description_lenght | 产品说明长度 |
| product_photos_qty | 产品照片数量 |
| product_weight_g | 产品重量单位g |
| product_length_cm | 产品长度单位cm |
| product_height_cm | 产品高度单位cm |
| product_width_cm | 产品宽度单位cm |
合并数据表¶
合并几个数据表,得到一个涵盖交易基本信息的基础数据集
| 表名 | 导入名 | 说明 |
|---|---|---|
| olist_Order Dataset.csv | orders | 订单信息 |
| olist_Payments Dataset.csv | payments | 支付信息 |
| olist_Order Items Dataset.csv | order_items | 商品信息 |
| olist_customers_dataset.csv | customers | 客户信息 |
# 合并表
order_payment = pd.merge(orders,payments, on='order_id',how='left')
payorder_customer = pd.merge(order_payment,customers, on='customer_id',how='left')
basic_data = pd.merge(payorder_customer,order_items, on='order_id',how='left')
basic_data.info()
# 预览数据集
basic_data.head()
# 统计缺失值数量和占比
def missing_info(data,num):
# func:统计缺失值数量和占比函数
# data: dataframe类型
# num: 数字类型,显示前几行数据
# return: 缺失值统计\占比
null_data = data.isnull().sum().sort_values(ascending=False)
percent_1 = data.isnull().sum()/data.isnull().count()
missing_data = pd.concat([null_data,percent_1.apply(lambda x: format(x, '.2%'))],axis=1,keys=['total missing','missing percentage'])
print(missing_data.head(num))
missing_info(basic_data,15)
缺失值处理:
- order_delivered_customer_date、order_delivered_carrier_date 字段缺失值数量分别为3229,2074,相对其他缺失数据较多,但是占整体数据较少仅 2.87%,1.75%,,可直接删除缺失值。
- 其他字段的缺失值与整体数据相比就更少了,亦可删除。
# 删除缺失值
basic_data = basic_data.dropna()
basic_data.info()
异常值处理¶
# 观察数据异常情况
basic_data.describe()
异常值情况
payment_installments 最小值为0
- 付款要么一次性付清,要么分期付款,而分期付款一般有3、6、12、24期等。
- 分期付款期数为1时,说明用户是一次性付清,没有分期。所以这里为0是异常值
payment_value 最小值为0
- 支付金额为0的情况有点异常,但不排除是使用代金券或者礼品卡。需要查询详细数据。
# 查询异常值的详细数据 payment_installments
basic_data[basic_data['payment_installments']==0]
可以看出,异常数据的支付金额不为0,并使用借记卡进行支付,但分期付款期数为0,明显矛盾,删除这类异常值
# 查询异常值的详细数据 payment_installments
basic_data[basic_data['payment_value']==0]
可以看到,异常数据的支付方式是代金券,印证了之前的想法,说明这类数据不属于异常值
异常数据加起来一共2条,可根据 index 删除
# 删除异常值
basic_data=basic_data.drop(index=basic_data[basic_data['payment_installments']==0].index)
basic_data.describe()
# 查看数据的信息
basic_data.info()
重复值处理¶
# 查看每一行数据是否存在重复值
basic_data.duplicated().sum()
没有重复值,不需要进行处理。
数据类型转化¶
# 日期时间数据类型转化的函数
def transform_datetime(data,column_list):
# func: 日期时间字符串转化函数
# data: dataframe类型
# num: 数字类型,显示前几行数据
# return: 日期时间类型数据
for i in column_list:
data[i] = pd.to_datetime(data[i])
print('日期时间数据类型转化完成')
data = basic_data
column_list =['order_purchase_timestamp','order_approved_at','order_delivered_carrier_date','order_delivered_customer_date','order_estimated_delivery_date']
transform_datetime(data,column_list)
数据清洗后
- 样本大小:115015 条数据
- 字段:22个
- 有少量缺失值,已删除
- 有少量异常值,已删除
- 无重复值
导出到数据库¶
# 导出到 mysql 数据库的函数
def export_mysql(data,user,password,host_port,db,table_name):
# func: 导出到 mysql 数据库函数
# data: Dataframe 类型
# user: 用户名
# password: 密码
# host_port: 主机,端口
# db: 数据库名
# table_name: 表名
print('将清洗后的数据导出到 mysql')
engine = create_engine("mysql+pymysql://{}:{}@{}/{}".format(user, password, host_port, db))
con = engine.connect()#创建连接
data.to_sql(table_name,engine,if_exists='replace',index=False)
print('成功导出')
user = 'root'
password = '1234567890'
host_port = '127.0.0.1:3306'
db = 'test'
data = basic_data
table_name = 'basic_data'
export_mysql(data,user,password,host_port,db,table_name)
模块一:基础属性¶
客户地理位置分布情况¶
各州、城市客户分布¶
Olist 客户主要集中在7个州和9个城市,巴西圣保罗州(SP)、里约热内卢州(RJ)、米纳斯吉拉斯州(MG)这三个州的客户数处于前列。其中,巴西圣保罗州(SP)是客户数最多的州,占总客户数的 41.94%,而客户数分布最多的城市是巴西圣保罗州的 sao paulo(圣保罗) ,约占 15.56%
城市购买力排名¶
购买力排名的前三强为 sao paulo(圣保罗),rio de janeiro(里约热内卢),belo horizonte(贝洛奥里藏特)
模块二:行为偏好¶
客户购物偏好¶
客户付款方式偏好¶
115015个订单中,客户付款方式首选信用卡 credit_card 支付,占比高达73.81%,其次是通过线下付款的方式 boleto(巴西主流的线下支付工具),占比19.43%,代金券 voucher 和借记卡 debit_card 分别占比5.32%和1.44%。
客户购物时间偏好¶
- 客户下单时间主要集中在早上9:00到晚上22:00
- 工作日的订单量和销售金额表现优于周末
模块三:交易属性¶
- 新老客户占比
- 客户消费行为分析
- RFM 客户价值分层
# 新增字段:购买日期,购买年月
basic_data['order_date'] = basic_data['order_purchase_timestamp'].dt.date
basic_data['order_yearmonth'] = basic_data['order_purchase_timestamp'].dt.to_period('M')
# 客户首次购买时间和最近一次购买时间
user_life = basic_data.groupby('customer_unique_id',as_index=False).order_date.agg([min,max])
user_life.head()
# 客户首次购买时间和最近一次购买时间分布
fig,axes=plt.subplots(1,2,figsize=(17,6)) #创建一个一行两列的画布
user_life['min'].value_counts().plot(ax=axes[0])
axes[0].set_title('客户首次购买时间分布')
axes[0].set_xlabel('时间(月份)')
axes[0].set_ylabel('客户数')
user_life['max'].value_counts().plot(ax=axes[1])
axes[1].set_title('客户最近一次购买时间分布')
axes[1].set_xlabel('时间(月份)')
axes[1].set_ylabel('客户数')

# 查询只进行过一次购买的客户数
new_old = (user_life['min'] == user_life['max']).value_counts(normalize=True)
new_old
- 从分布可以看到,
- 客户第一次购买的分布和最近一次购买的分布十分相识,说明大部分用户只购买了一次,就再也没有购买过了。
- 在2017年11月,新用户数暴涨。
- 从客户数可以看出,新客户数占总客户数97.8%,老客户数占总客户数2.2%
新老客户贡献占比¶
再结合新老客户贡献占比情况,可以得出,大部分客户只购买一次,说明该电商平台在老客户维系工作方面没有到位,亟需改善。
客户消费行为分析¶
按照客户的消费行为,对客户简单划分成几个层:新用户、活跃用户、不活跃用户、回流用户。
- 新客户:第一次消费的客户
- 活跃客户:连续两个时间窗口都消费过的客户
- 不活跃客户:时间窗口内没有消费过的活跃客户
- 回流客户:回流客户是在上一个窗口中没有消费,而在当前时间窗口内有过消费
这里把时间窗口定为1个月
# 求每月每位客户的消费次数,用户 id 为 index, 月为 column
# 次数为的地方是 NAN,把 NAN 填充为0
purchase_times = pd.pivot_table(basic_data,index=("customer_unique_id"),columns=("order_month"),values=("order_date"),aggfunc=("count")).fillna(0)
purchase_times.head()
#每个用户每月消费次数有0次,1次,2次,n 次。这里把有消费次数的变为1,没有消费变为0
purchase_times = purchase_times.applymap(lambda x:1 if x>0 else 0)
purchase_times.head()
对访客进行判断,判断逻辑如下图:
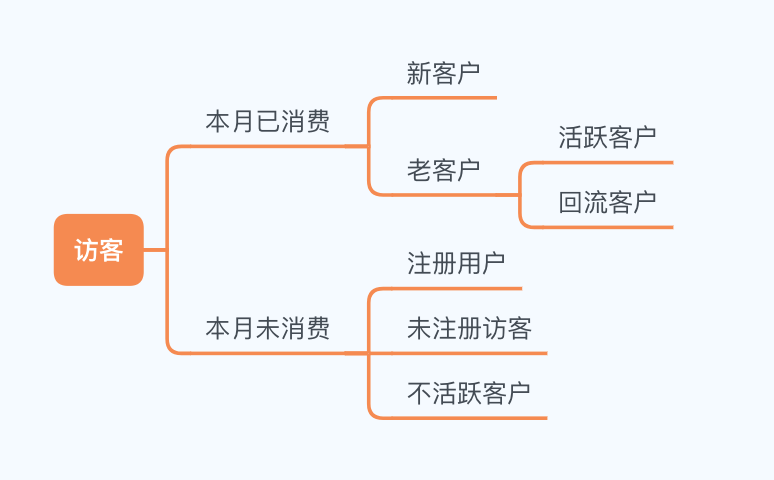
# 判断用户活跃与否,消费与否的函数
def active_status(data):
status = []
# 这里一共有22个月
for i in range(22):
# 本月未消费
if data[i] == 0:
if len(status) > 0:
if data[i-1] == '注册用户/未注册访客':
status.append('注册用户/未注册访客')
else:
status.append('不活跃客户')
else:
status.append('注册用户/未注册访客')
# 本月消费过
else:
if len(status) == 0:
status.append('新客户')
else:
if data[-1] == '不活跃客户':
status.append('回流客户')
elif data[-1] == '注册用户/未注册访客':
status.append('新客户')
else:
status.append('活跃客户')
# 将列表转化为 series
return pd.Series(status)
purchase_status = purchase_times.apply(active_status,axis=1)
purchase_status.head()
# 由于返回的 dataframe 列名发生了改变,我们需要重新倒入列名。
purchase_columns = basic_data.order_month.sort_values().unique()
purchase_status.columns = purchase_columns
purchase_status.head()
# 将注册用户/未注册访客替换为空值,这样 count 计算时不会计算到,并统计每月各状态客户数量。
purchase_status_count = purchase_status.replace('注册用户/未注册访客',np.NaN).apply(lambda x:pd.value_counts(x))
purchase_status_count.head(5)
# 用0填充NaN
# 使用 .T 对 dataframe 数据进行转置,并可视化
ax = purchase_status_count.fillna(0).T.plot(kind="area",figsize = (12,6))
ax.set_xlabel('时间(月)')
ax.set_ylabel('客户数(人)')
ax.set_title('每月各类客户类型占比面积堆叠图')

由图可知,
- 蓝色的不活跃客户始终是占据大头的,这也跟我们之前的图表结果相符,大部分客户只购买一次。
- 绿色的活跃客户相对稳定,是属于核心客户群。
- 橙色的新客户,相对稳定。
- 回流用户为零。
结合不活跃客户和回流用户,如果电商平台能在老客户维系工作上取得突破,会给平台带来很大的增长空间。
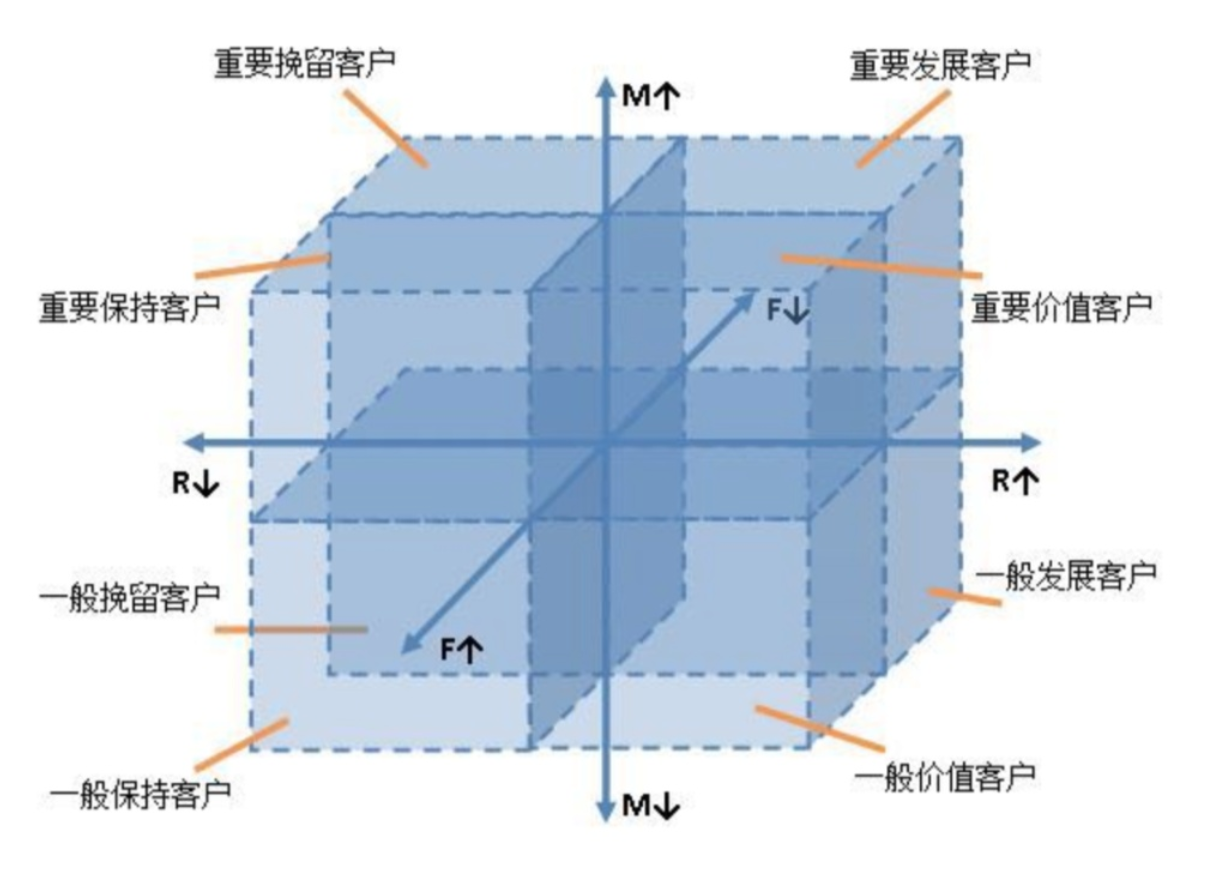
RFM模型细分客户价值¶
- R(Recency):客户最近一次交易时间的间隔。R值越大,表示客户交易发生的日期越久,反之则表示客户交易发生的日期越近。
- F(Frequency):客户在最近一段时间内交易的次数。F值越大,表示客户交易越频繁,反之则表示客户交易不够活跃。
- M(Monetary):客户在最近一段时间内交易的金额。M值越大,表示客户价值越高,反之则表示客户价值越低。
获取 RFM 三个指标¶
# 获取指标
rfm_table=pd.pivot_table(basic_data,index=["customer_unique_id"],values=['order_purchase_timestamp',"order_id","payment_value"],aggfunc={"order_purchase_timestamp":"max","order_id":"count","payment_value":"sum"})
rfm_table.info()
R值¶
R值最近一次消费时间表示用户最近一次消费距离统计时间,消费时间越近的客户价值越大。所以要将 order_purchase_timestamp 里面具体的日期变成R中的天数。
假设统计时间是数据中日期时间最大那天
# 两个日期相减
rfm_table['R'] = (rfm_table['order_purchase_timestamp'].max() - rfm_table['order_purchase_timestamp'])
# 获取天数差
rfm_table['R'] = rfm_table['R'].map(lambda x:x.days)
rfm_table['R'].head()
F值、M值¶
再将 order_id 和 order_total 重命名为F、M
# 为了助于理解,对字段进行更名处理
rfm_table.rename(columns={"order_id":"F","payment_value":"M"},inplace=True)
rfm_table.head()
# 查看数据信息
rfm = rfm_table[["R","F","M"]]
rfm.info()
确定分层基线¶
观察R、F、M的分布情况,找到合适的基线对R、F、M 进行分层
# 观察数据基本情况
rfm.describe()
# 查看分布情况
import matplotlib.pyplot as plt
plt.figure(figsize=(10,5))
fig,axes=plt.subplots(3,1,figsize=(20, 20)) #创建一个一行三列的画布
sns.distplot(rfm['R'],ax=axes[0]) #左图
sns.distplot(rfm['F'],kde=False,ax=axes[1]) #中图
sns.distplot(rfm['M'],kde=False,ax=axes[2]) #右图

从上可得
- R值采用中位数进行划分
- F值存在很严重的偏态分布,F的数值大多集中在1,即消费频次只有1次,至少占整体75%,最大值为75。无法使用分位数方法来均分出2个等级,为了体现出区分度,这里使用自定义区间 bins= [1,75] 进行划分。
- M值存在很严重的偏态分布,75%的M数值小于201.74,最大值为 109312.64,这里使用四分之三位数进行划分。
构造 RFM 模型¶
(三个指标的权重一致)
一般而言,消费类的数据呈现长尾分布,都是长尾形态。80%甚至90%以上都集中在低频低额区间,少数的用户贡献了收入的大头,俗称二八法则。采用平均数无法很好的体现数组的特性,长尾用户很容易被平均。基线根据数据分布情况而定。
注意:由于R值的大小和用户价值呈现反比,所以高于基线的时候算低纬度,低于基线时算高纬度。
R
- 基线
- 中位数
- 规则
- 高于基线为0(低纬度)
- 低于基线为1(高纬度)
- 基线
F
- 基线
- [1,75]
- 规则
- 高于基线为1(高纬度)
- 低于基线为0(低纬度)
- 基线
M
- 基线
- 四分位数
- 规则
- 高于基线为1(高纬度)
- 低于基线为0(低纬度)
- 基线
# 对 R、F、M 划分
rfm['r_quartile'] = pd.qcut(rfm['R'], 2, labels=['1','0'])
rfm['f_quartile'] = pd.cut(rfm['F'], bins=[0,1,75], labels=['0','1'])
rfm['m_quartile'] = pd.qcut(rfm['M'], [0,0.75,1], labels=['0','1'])
rfm.head()
# 计算出 RFM 的总分
rfm['RFM_Score'] = rfm.r_quartile.astype(str)+ rfm.f_quartile.astype(str) + rfm.m_quartile.astype(str)
rfm.head()
# 筛选出重要价值客户
rfm[rfm['RFM_Score']=='111'].sort_values('M', ascending=False).head()
将 RFM 总分映射为客户八大类
| RFM 总分 | 客户类别 |
|---|---|
| 111 | 重要价值客户 |
| 011 | 重要保持客户 |
| 101 | 重要发展客户 |
| 001 | 重要挽留客户 |
| 111 | 一般价值客户 |
| 011 | 一般保持客户 |
| 101 | 一般发展客户 |
| 001 | 一般挽留客户 |
# RFM 总分映射为八类客户
customer_classification = {
"111":"重要价值客户",
"011":"重要保持客户",
"101":"重要发展客户",
"001":"重要挽留客户",
"110":"一般价值客户",
"010":"一般保持客户",
"100":"一般发展客户",
"000":"一般挽留客户",
}
rfm['customer_class'] = rfm['RFM_Score'].map(customer_classification)
rfm.head()
导出到 mysql 数据库¶
# 导出数据库
data = rfm
table_name = 'RFM_data'
export_mysql(data,user,password,host_port,db,table_name)
客户价值细分¶
# 合并数据集
review_data = pd.merge(basic_data,reviews, on='order_id',how='left')
print('合并后数据集所有字段\n',review_data.columns.values)
print('==='*15)
# 选取子集
review_data = review_data[['order_id','customer_unique_id','order_purchase_timestamp','review_id','review_score','review_creation_date','review_answer_timestamp']]
review_data.info()
各个字段说明如下
| 字段 | 说明 |
|---|---|
| order_id | 订单ID |
| customer_unique_id | 客户唯一标识符 |
| order_purchase_timestamp | 下单时间 |
| review_id | 满意度调查ID |
| review_score | 评价得分,1到5分(假设5分最好) |
| review_creation_date | 发出满意度调查日期 |
| review_answer_timestamp | 客户满意度回复日期 |
清洗数据集¶
# 预览数据集
review_data.head()
# 统计缺失值数量和占比
missing_info(review_data,10)
# 观察数据异常情况
review_data.describe()
# 查看数据信息
review_data.info()
# 查看每一行数据是否存在重复值
review_data.duplicated().sum()
# 查看重复数据
review_data[review_data.duplicated() == True]
# 处理重复数据
review_data = review_data.drop_duplicates()
review_data.info()
# 转化格式
data = review_data
column_list =['order_purchase_timestamp','review_creation_date','review_answer_timestamp']
transform_datetime(data,column_list)
# 导出数据库
data = review_data
table_name = 'review_data'
export_mysql(data,user,password,host_port,db,table_name)
客户满意度调查情况¶
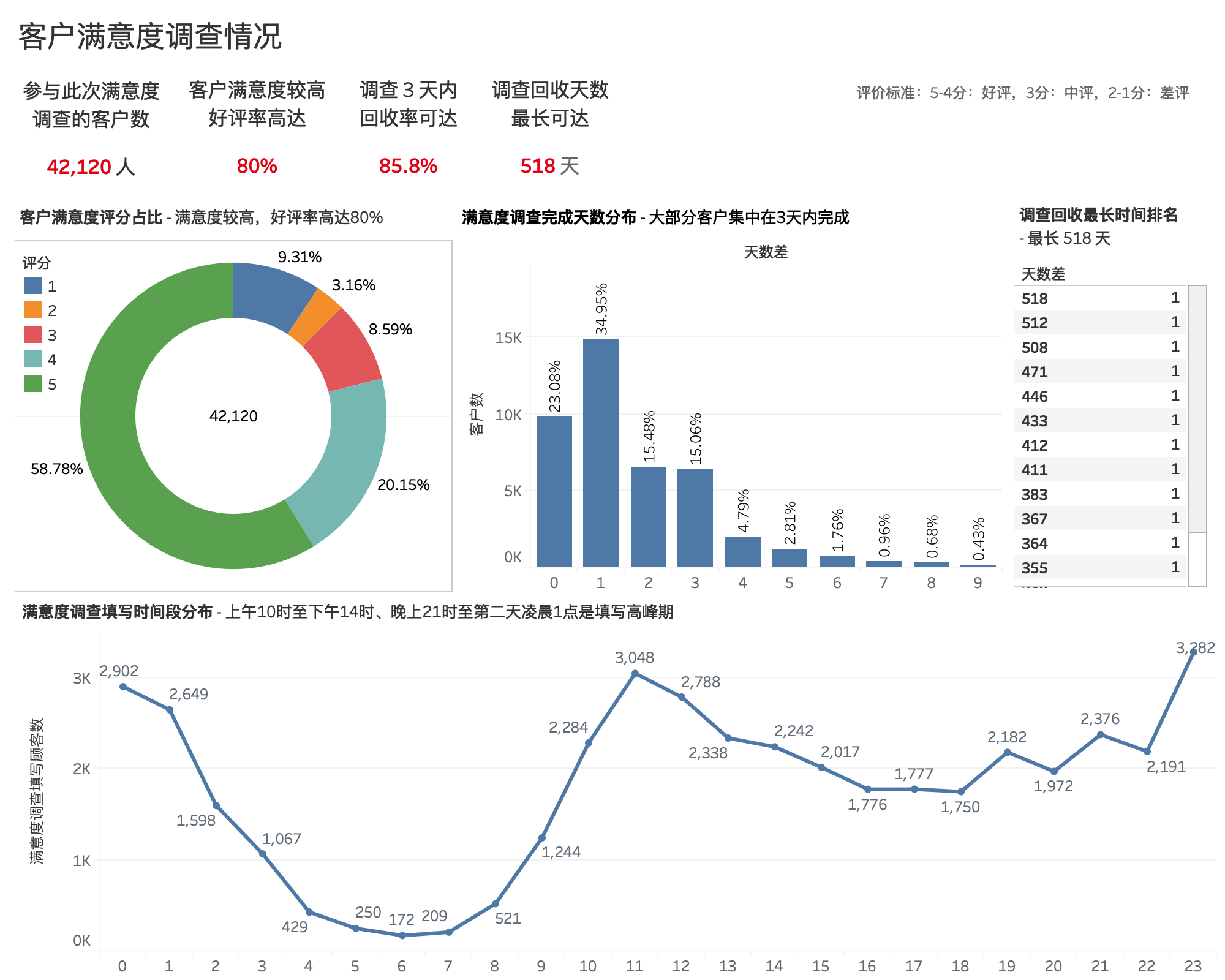
客户满意度评分占比¶
- 客户对该电商平台满意度较高,好评率高达80%。
- 以(1-2分:差评,3分:中评,4-5分:好评)为评价标准。参与满意度调查的客户数一共有4,213名,其中评价5分占比最高,为58.78%,4分占比20.15%,好评率近80%,用户满意度较高;但1分和2分合计占比12.4%左右,平台还有一定的提高空间。
客户满意度调查填写时间段¶
- 上午10时至下午14时、晚上21时至第二天凌晨1点这两个时间段是客户完成调查的高峰期
客户满意度调查完成天数¶
- 满意度调查发布3天内,回收率达 85.8%
- 大部分客户会在调查发布当天或者隔1-3天填写并提交
- 1-3天内未填写的客户,大概率会遗忘,调查回收最长可达 518 天
建议
- 为了,提高调查回收率,建议调查发布1周后,提醒未填写的用户
- 可选择在上午10时至下午14时、晚上21时至第二天凌晨1点这两个时间段发布满意度调查或者提醒尚未填写的客户
# 合并数据集
res = pd.merge(basic_data,products, on='product_id',how='left')
pro_data = pd.merge(res,pro_trans, on='product_category_name',how='left')
print('合并后数据集所有字段\n',pro_data.columns.values)
print('==='*15)
# 选取子集
product_data = pro_data[['order_id','order_item_id','customer_unique_id','product_id','product_category_name_english','price','freight_value','payment_value','order_status','order_purchase_timestamp']]
product_data.info()
# 预览数据集
product_data.head()
# 统计缺失值数量和占比
missing_info(product_data,10)
缺失值处理:
- product_category_name_english 字段缺失值数量为1650,相对其他缺失数据较多,但是与整体数据相比较少,只占 1.43%,可删除缺失值。
# 删除缺失值
product_data = product_data.dropna()
product_data.info()
# 观察数据异常情况
product_data.describe()
# 查看每一行数据是否存在重复值
product_data.duplicated().sum()
# 查看重复数据
product_data[product_data.duplicated() == True]
# 去重处理
product_data = product_data.drop_duplicates()
product_data.info()
# 转化格式
data = product_data
column_list =['order_purchase_timestamp']
transform_datetime(data,column_list)
# 导出数据库
data = product_data
table_name = 'pro_data'
export_mysql(data,user,password,host_port,db,table_name)
处理数据¶
使用 basic_data 构造整体销售情况子数据集 sales_data。
# 预览数据集 basic_data
basic_data.head()
# 新增日期字段、年份、月份字段
basic_data['order_date'] = basic_data['order_purchase_timestamp'].dt.date
basic_data['order_year'] = basic_data['order_purchase_timestamp'].dt.year
basic_data['order_month'] = basic_data['order_purchase_timestamp'].dt.month
sale_data = basic_data[['order_date','customer_unique_id','payment_value','order_year','order_month']]
sale_data.head()
# 按照年份、月份对销售子数据集进行分组求和、计数,得到订单日期、销售额、客户数、订单量、年份、月份信息
sales_year = sale_data.groupby(['order_year','order_month']).agg({"order_date":"count","payment_value":"sum","customer_unique_id":"nunique"})
sales_year.rename(columns={"order_date":"order_number","payment_value":"total_pay","customer_unique_id":"customer_number"},inplace=True)
sales_year.head()
# 对以上数据进行拆分,每年为一个表。
year_2016 = sales_year.loc[2016,:].copy()
year_2017 = sales_year.loc[2017,:].copy()
year_2018 = sales_year.loc[2018,:].copy()
year_2016 # 看一下2016年的数据
销售额分析¶
构建销售额表
# 构建销量表
sales=pd.concat([year_2016['total_pay'],year_2017['total_pay'],
year_2018['total_pay']],axis=1)
# 填充 NAN 值为0
sales =sales.fillna(0)
# 对行名和列名进行重命名
sales.columns=['Sales-2016','Sales-2017','Sales-2018']
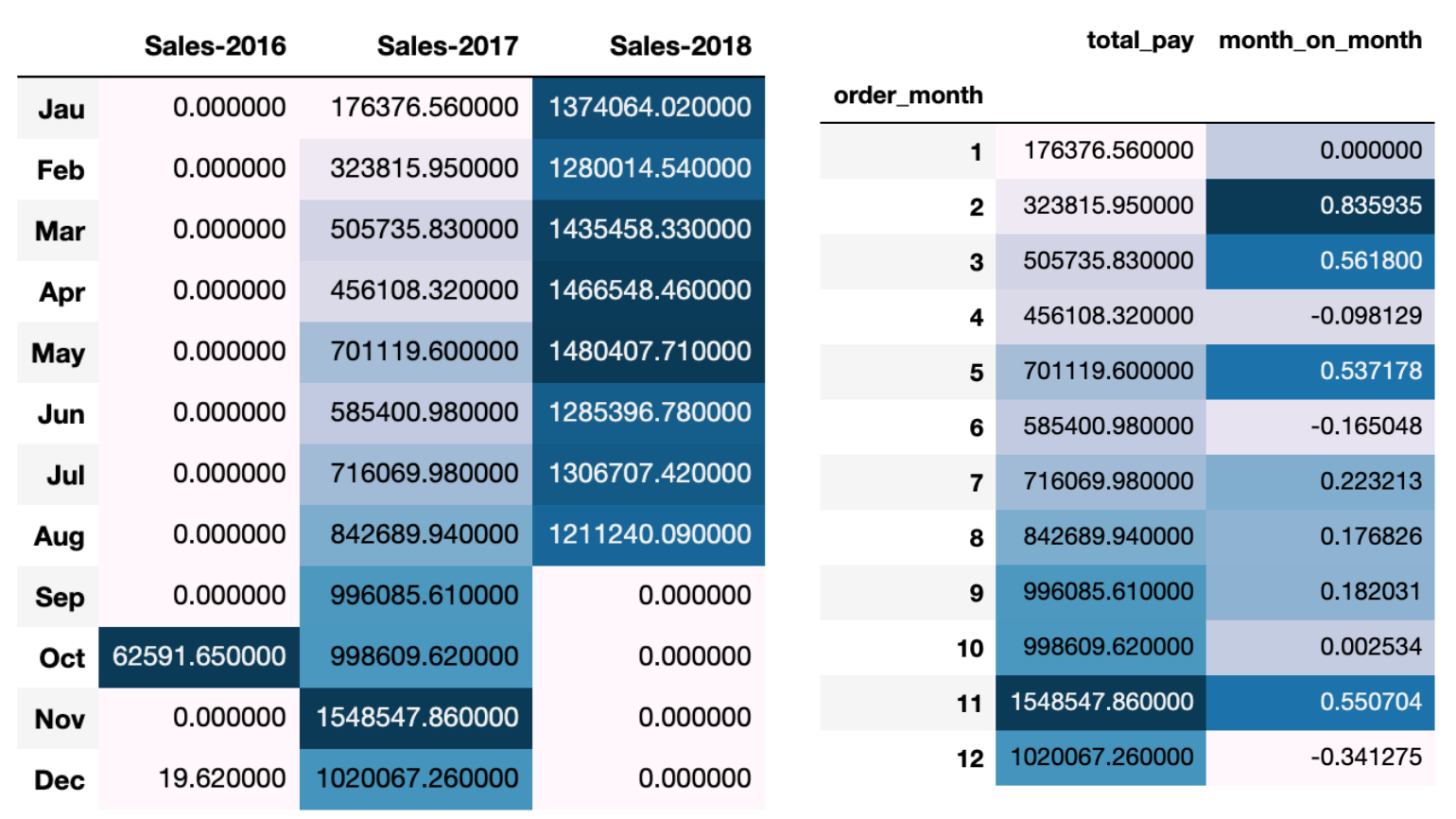
sales.index=['Jau','Feb','Mar','Apr','May','Jun','Jul','Aug','Sep','Oct','Nov','Dec']
# 颜色越深,销售额越高
sales.style.background_gradient()
结合上图可以看出,只有2017年的数据是整年的,2016和2018都或多或少不完整,所以这里只分析2017年的数据。
2017年整体销售额表现¶
- 2017年销售额整体呈上升趋势,在11月销售金额达到顶峰,且远高于其他月份,1月销售金额最低,3,5月达到了阶段性的小高峰;
- 总的来说,后半年的表现远好于前半年,而且随着月份的增大,销售额也有明显的增加。
肉眼可见的是每月的销售额逐步增长,来实际计算一下具体的增长率。
# 计算环比
for i in range(1,len(year_2017)+1):
if i == 1:
year_2017.loc[i,'month_on_month'] = 0
else:
year_2017.loc[i,'month_on_month'] = (year_2017.loc[i,'total_pay'] - year_2017.loc[i-1,'total_pay'])/year_2017.loc[i-1,'total_pay']
year_2017[["total_pay","month_on_month"]].style.background_gradient()
# 构建订单数量信息表
orders=pd.concat([year_2016['order_number'],year_2017['order_number'],
year_2018['order_number']],axis=1)
# 填充 NAN 值为0
orders =orders.fillna(0)
# 对行名和列名进行重命名
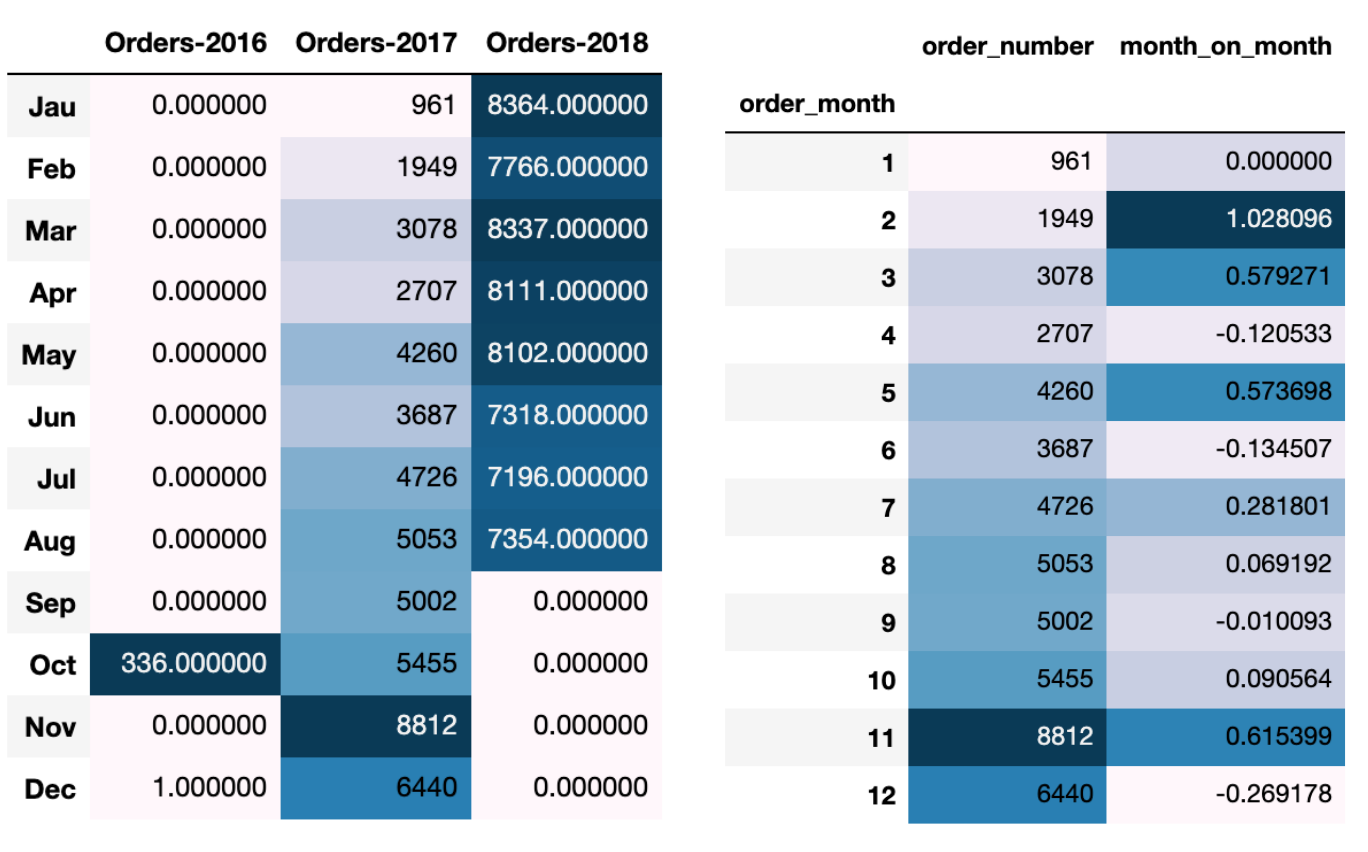
orders.columns=['Orders-2016','Orders-2017','Orders-2018']
orders.index=['Jau','Feb','Mar','Apr','May','Jun','Jul','Aug','Sep','Oct','Nov','Dec']
# 颜色越深,订单量越高
orders.style.background_gradient()
2017年整体订单量表现¶
从上面可以看出,2017年订单量变化趋势与销售额是一样的,下半年整体高于上半年。
# 计算环比
for i in range(1,len(year_2017)+1):
if i == 1:
year_2017.loc[i,'month_on_month'] = 0
else:
year_2017.loc[i,'month_on_month'] = (year_2017.loc[i,'order_number'] - year_2017.loc[i-1,'order_number'])/year_2017.loc[i-1,'order_number']
year_2017[["order_number","month_on_month"]].style.background_gradient()
2017年每月订单量增长率表现¶
从上面可以看出,2017年订单量增长率变化与销售额增长率是一样的,2、3、5、11月增速较快,其他月份表现平平。。
# 2016-2018年客单价表
aovs=pd.concat([year_2016['total_pay'],year_2016['customer_number'],year_2017['total_pay'],year_2017['customer_number'],
year_2018['total_pay'],year_2018['customer_number']],axis=1)
# 对行名和列名进行重命名
aovs.columns=['Sales-2016','customers-2016','Sales-2017','customers-2017','Sales-2018','customers-2018']
aovs.index=['Jau','Feb','Mar','Apr','May','Jun','Jul','Aug','Sep','Oct','Nov','Dec']
# 填充 NAN 值为0
aovs =aovs.fillna(0)
# 颜色越深,销售额越高
aovs.style.background_gradient()
# 2017年客单价
aovs_info=pd.concat([year_2016['total_pay']/year_2016['customer_number'],year_2017['total_pay']/year_2017['customer_number'],year_2018['total_pay']/year_2018['customer_number']],axis=1)
# 对行名和列名进行重命名
aovs_info.columns=['AOV-2016','AOV-2017','AOV-2018']
aovs_info.index=['Jau','Feb','Mar','Apr','May','Jun','Jul','Aug','Sep','Oct','Nov','Dec']
# 填充 NAN 值为0
aovs_info =aovs_info.fillna(0)
# 颜色越深,销售额越高
aovs_info.style.background_gradient()